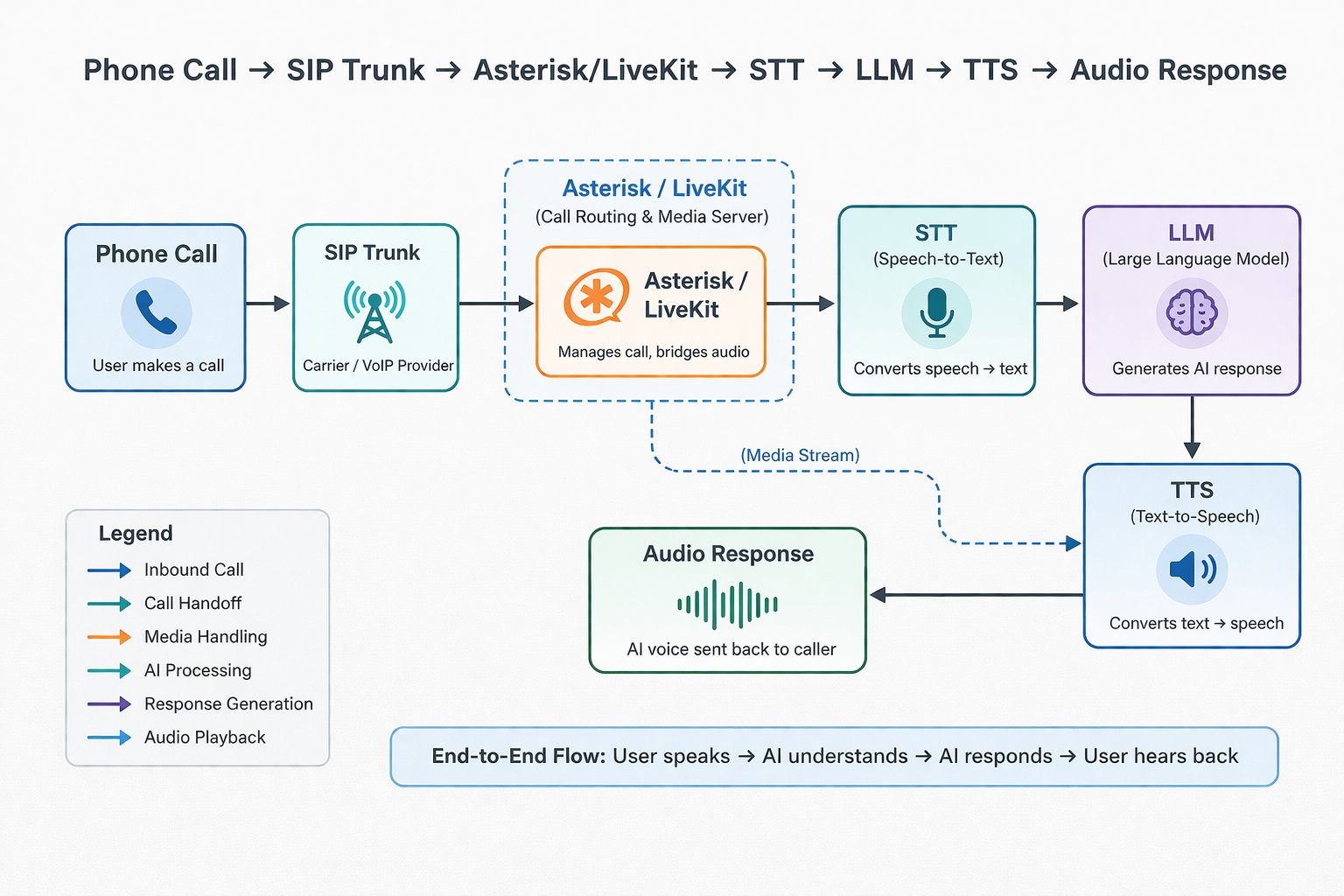
Sub-200ms on phone calls is achievable when you architect for streaming and parallelism across STT, LLM, and TTS — instead of waiting for full utterances at each stage. Here is the call flow:
The key insight: these stages run in parallel via streaming, not sequentially. STT sends partial transcripts to the LLM before the user finishes speaking. The LLM starts generating tokens on partial input. TTS starts synthesizing audio from the first tokens. The result is overlapping execution that makes the pipeline feel instantaneous.
Two architecture paths
Option 1: Asterisk + ExternalMedia (fully self-hosted)
Install Asterisk on the server. It handles SIP trunks, inbound DIDs, and outbound dialing. Use ARI (Asterisk REST Interface) + ExternalMedia to create a mixing bridge that pipes RTP audio to your AI process over UDP on localhost. Your Python/Go service decodes PCM, runs it through STT, feeds the LLM, generates TTS audio, and sends PCM back to the bridge. This is the "roll your own Twilio Media Streams" approach — full control, no per-minute fees.
Option 2: LiveKit Agents + SIP (modern media stack)
Self-host LiveKit Server on the same machine. It handles WebRTC/SIP sessions and routes low-latency audio to agent processes. LiveKit Agents SDK registers workers that receive audio frames for each call and pipe them through your local STT/LLM/TTS stack. Supports barge-in, turn detection, and multi-participant rooms out of the box.
Best LLMs for voice latency
For real-time voice agents, time-to-first-token (TTFT) is the critical metric — it determines when the response starts streaming to TTS. Target under 300ms for the LLM stage.
3–7B open models (Llama 3.1 8B, Mistral 7B variants) are the sweet spot for self-hosting. They hit 50–400ms TTFT depending on prompt length and quantization. Run them via vLLM or TensorRT-LLM for optimized inference with streaming output.
For TTS, Microsoft VibeVoice-Realtime-0.5B is an open-source MIT-licensed model achieving ~300ms latency via streaming generation — a strong option to avoid paid TTS APIs.
Turn detection and barge-in
Phone users talk over each other. You need VAD (Voice Activity Detection) + turn detection to allow interrupting the bot and cutting off TTS playback instantly. LiveKit's framework uses Silero VAD and a multilingual turn detector designed for telephony participants.